Adamの収束の速さとSGDの汎化性能の良さの良いとこ取りなoptimizerである、AdaBoundとAMSBoundをラーメン二郎データセットの転移学習に対して試してみました。
AdaBound と AMSBound 自体の詳細については [最新論文] 新しい最適化手法誕生! AdaBound & AMSBound が参考になりますので、こちらの記事または、提案論文(arXiv) をご覧ください。
(2019年6月13日追記) Adam, AMSGrad で weight decay=0 の設定、および、AdaBound, AMSBound で final_lr=0.5 の設定で追加検証した結果を記事末尾に追記しました。試した中では、AdaBound(final_lr=0.5)が最も良い結果となりました。
ざっくり概要
- ラーメン二郎データセットで AdaBound と AMSBound を試してみた(ResNet50の転移学習)
- 比較したOptimizerは SGD, Adam, AMSGrad, AdaBound, AMSBound の5種類
- 転移学習においてもほぼ論文の主張どおりの結果 (AdaBound と AMSBound の速い収束、高い汎化性能)を確認できた
実装
論文著者が公開している実装 Luolc/AdaBound を knjcode/pytorch-finetuner に組み込んで試しました。
実施内容
学習データセット
ラーメン二郎データセットは現在約9万枚あり、すべて利用して学習すると時間がかかるため、各店舗500枚に限定した縮小版の二郎データセットを用意して利用しました。
データセット詳細 (計 26,400枚)
- 40店舗(クラス)
- 学習データ 20,000枚 (各店舗 500枚)
- 評価データ 3,200枚 (各店舗 80枚)
- テストデータ 3,200枚 (各店舗 80枚)
学習条件
共通設定
- モデル: ResNet50 (ImageNet学習済みモデルを転移学習, 全層再学習(レイヤーフリーズ無し))
- バッチサイズ: 256
- 学習回数: 10回
- エポック数: 120 (60, 90 エポックで学習率を0.1倍)
- warmup epoch: 5 (学習率を徐々に増加し5epoch目に学習率の初期値となるよう調整)
デフォルトのデータ拡張として以下を実施
- RandomRotation (degree=3.0)
- RandomResizedCrop (crop_scale=0.08,1.0 crop_aspect=0.75,1.3333333333333333)
- RandomHorizontalFlip (p=0.5)
学習時のValidationは画像の短辺を224pxにリサイズ後にセンタークロップして利用しています (ImageNetのValidationの場合256pxにリサイズ後に224pxにクロップすることが多いですが、ラーメン二郎画像の場合は画像の端まで使う方が精度が良いため上記の設定にしています)
optimizer毎の学習パラメータ詳細
| optimizer | lr | lr step epoch (factor 0.1) | mom | weight decay | betas | final lr | gamma |
|---|---|---|---|---|---|---|---|
| SGDM | 0.1 | 60, 90 | 0.9 | 5e-4 | – | – | – |
| Adam | 0.001 | 60, 90 | – | 5e-4 | 0.9, 0.999 | – | – |
| AMSGrad | 0.001 | 60, 90 | – | 5e-4 | 0.9, 0.999 | – | – |
| AdaBound | 0.001 | 60, 90 | – | 5e-4 | 0.9, 0.999 | 0.1 | 0.001 |
| AMSBound | 0.001 | 60, 90 | – | 5e-4 | 0.9, 0.999 | 0.1 | 0.001 |
SGDM (SGD with momentum), Adam, AMSGrad は pytorch付属のoptimizerを利用しています。
AdaBound, AMSBound については著者実装 Luolc/AdaBound を利用しています。
SGDM の learning rate について
SGDM の学習率の初期値 0.1 は、転移学習における値としては高めな値と感じるかもしれません。
本格的に検証する前に、SGDM については、
lr=0.1 or 0.01
lr_step_epoch=[60,90] or [30,60,90]
のそれぞれの組み合わせについて(各1回だけですが)試した結果、上記設定が最も正解率が高かったため採用しています。 (すべての試行で warmup epoch は 5epoch です)
検証結果
テストデータに対する正解率(平均値)と標準偏差
Validationデータセットでaccuracy最大となるepochのモデルを選び、テストデータでの正解率を確認(各モデル試行回数10回の平均)
| optimizer | average Top-1 test acc (%) | 標準偏差 |
|---|---|---|
| AdaBound | 95.86 | 0.0013 |
| AMSBound | 95.80 | 0.0021 |
| SGDM | 95.67 | 0.0019 |
| AMSGrad | 95.46 | 0.0032 |
| Adam | 95.28 | 0.0023 |
AdaBoundが最も正解率が高く、ばらつき(標準偏差)も少ない結果になりました。
AMSBoundもSGDより良い結果になっています。
10回の試行中のベストのモデルの正解率
平均値ではなく、Validationデータセットでの正解率がベストだったモデルにおけるテストデータでの正解率
| optimizer | Top-1 test acc (%) | 試行回数 | epoch |
|---|---|---|---|
| AMSBound | 96.09 | 2回目 | 118 |
| AdaBound | 96.03 | 4回目 | 112 |
| SGDM | 96.00 | 4回目 | 92 |
| AMSGrad | 95.81 | 5回目 | 119 |
| Adam | 95.72 | 5回目 | 106 |
10回の試行の平均ではなく、ベストの正解率のモデルの結果については AMSBound が最も良くなりました。
学習の推移
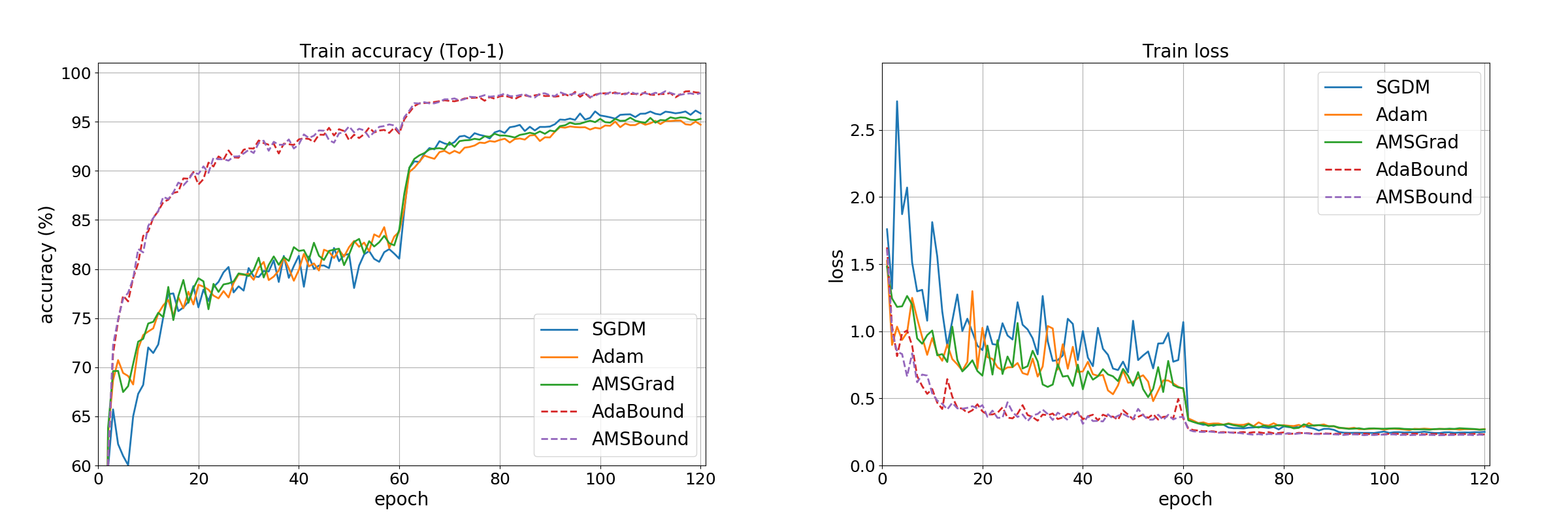
学習の序盤から終盤まで、 AdaBound と AMSBound が accuracy, loss ともに良好です。
Validation accuracyの推移 (各モデルでベストの正解率を記録した試行のログを採用)
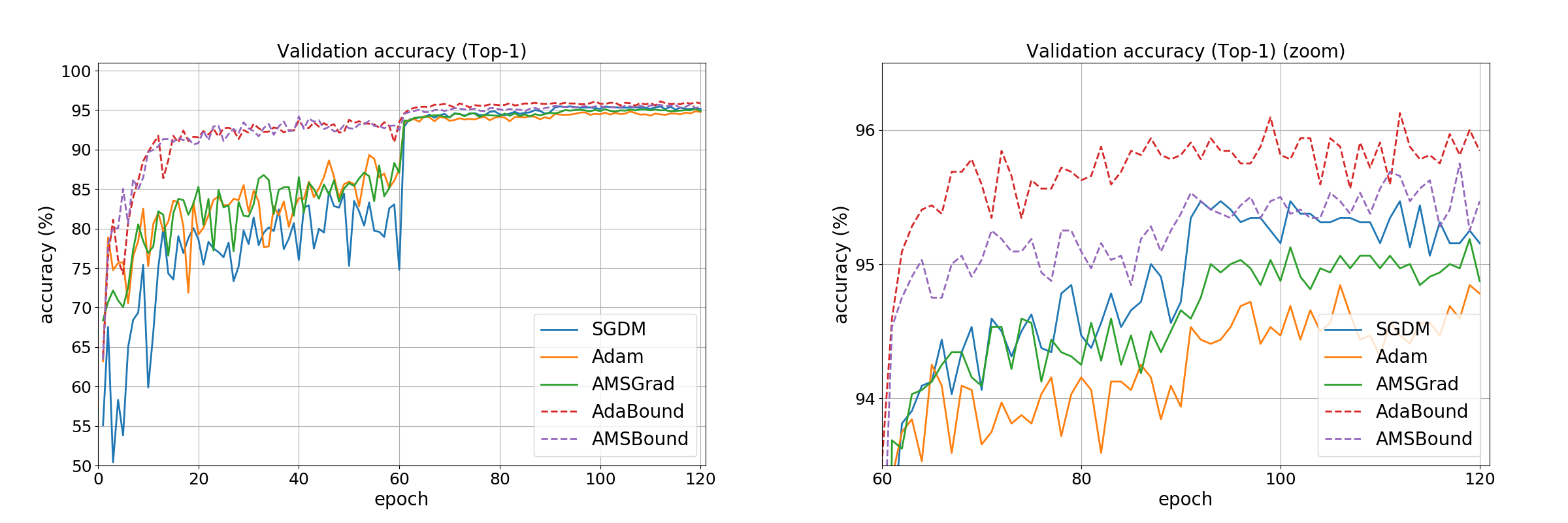
Validationデータセットについても学習の序盤から終盤まで、 AdaBound と AMSBound は収束が速く、accuracyも良い傾向が続きました。
Test accuracyの推移 (各モデルでベストの正解率を記録した試行のログを採用)
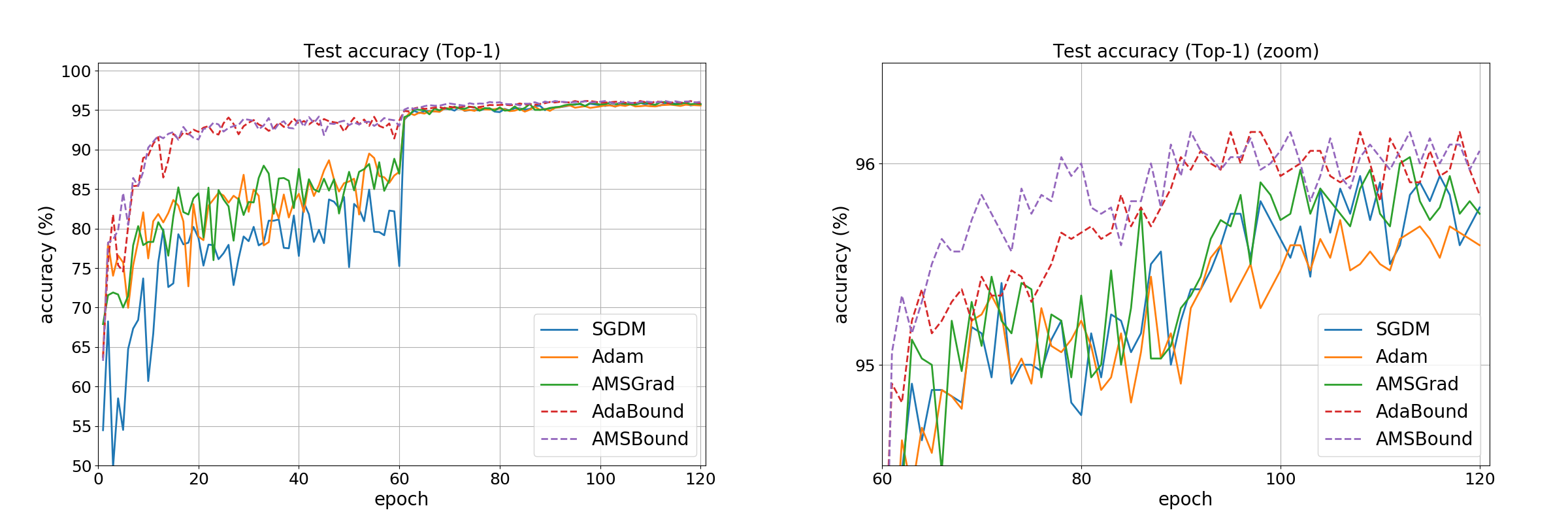
通常は各エポック毎にテストデータでの評価はしないですが、今回の検証ではテストデータについてもエポック毎の正解率を計測しました。
結果はValidationデータセット同様、 AdaBound と AMSBound の結果が良好でした。
今後
ラーメン二郎bot(@jirou_deep)にも使っている、単体モデルで現状最高精度のモデル(正解率約99.06%)は Momentum SGD を使い、warm restart有りのcosine annealingで250epoch程度学習しています。
時間があれば、全学習データと AdaBound を使って、このモデルを超えられるか試してみたいと思います。
(追記) Adamのweight decayおよびAdaBoundのfinal_lrを変更して追加の検証を実施
初回の検証では、AdaBoundの論文著者の検証設定に合わせて、すべてのOptimizerで、weight decay=5e-4 としていましたが、Adam や AMSGrad は weight decay=0 のほうが良い結果になる場合もあるため、追加で検証を実施しました。
さらに、AdaBound や AMSBound のパラメータである final_lr についても 0.1 ではなく 0.5 に設定した場合についても試してみました。
その他の設定については、初回検証時と合わせています。
追加検証結果
テストデータに対する正解率(平均値)と標準偏差
初回検証時と同様に、Validationデータセットでaccuracy最大となるepochのモデルを選び、テストデータでの正解率を確認(各モデル試行回数10回の平均)
| optimizer | avg Top-1 test acc (%) | 標準偏差 | 備考 |
|---|---|---|---|
| AdaBound (final=0.5) | 96.05 | 0.0030 | final_lr=0.5 |
| AMSGrad (wd=0) | 95.89 | 0.0029 | wd=0 |
| AMSBound (final=0.5) | 95.88 | 0.0023 | final_lr=0.5 |
| AdaBound | 95.86 | 0.0013 | final_lr=0.1 |
| Adam (wd=0) | 95.81 | 0.0018 | wd=0 |
| AMSBound | 95.80 | 0.0021 | final_lr=0.1 |
| SGDM | 95.67 | 0.0019 | wd=5e-4 |
| AMSGrad | 95.46 | 0.0032 | wd=5e-4 |
| Adam | 95.28 | 0.0023 | wd=5e-4 |
AdamとAMSGradのどちらも、weight decay を 0にすることで、正解率が改善しています。AMSGradについては、以前の検証で最も正解率の高かった AdaBound(final_lr=0.1)より良い正解率となっています。
また、AdaBound, AMSBound ともに、final_lr を 0.1 から 0.5 に変更することで、正解率が改善しており、AdaBound(final_lr=0.5)が最も良い結果となりました。
10回の試行中のベストのモデルの正解率
平均値ではなく、Validationデータセットでの正解率がベストだったモデルにおけるテストデータでの正解率
| optimizer | Top-1 test acc (%) | 施行回数 | epoch |
|---|---|---|---|
| AdaBound (final=0.5) | 96.66 | 10回目 | 118 |
| AMSGrad (wd=0) | 96.19 | 5回目 | 105 |
| AMSBound (final=0.5) | 96.31 | 3回目 | 105 |
| AdaBound | 96.03 | 4回目 | 112 |
| Adam (wd=0) | 96.09 | 4回目 | 119 |
| AMSBound | 96.09 | 2回目 | 118 |
| SGDM | 96.00 | 4回目 | 92 |
| AMSGrad | 95.81 | 5回目 | 119 |
| Adam | 95.72 | 5回目 | 106 |
10回の施行の平均ではなく、ベストの正解率を選んだ場合も final_lr=0.5 の AdaBound が最も良い結果となりました。